http://exploit-db.com/docs/39527.pdf
0x00 综述
在本文中,我们研究了如何利用安卓系统上最臭名昭著的漏洞之一Stagefright。在此之前,我们一直认为这个漏洞是很难被利用的。在研究中,我们大量参考了Google公布的文章-exploit-38226和研究报告Google Project Zero: Stagefrightened。
本文中呈现了我们的研究结果,详细的介绍了这个漏洞的局限性,提供了一种绕过ASLR的途径,并为后继者提出了一些研究建议。
NorthBit团队利用的这个漏洞,能够影响到 Android 2.2-4.0和5.0-5.1版本,同时,还能够绕过Android 5.0-5.1上的ASLR技术(Android 2.2-4.0版本上没有实现ASLR)。
0x01 Stagefright
Stagefright是Android系统中的一个多媒体库。直到2015年7月27日,几个关键堆溢出漏洞的曝光,人们才开始注意到了Stagefright。这个漏洞最初是由Zimperium的Joshua Drake发现的,Android版本包括从1.0到5.1都受到了影响。
在下面的部分中,我们会用“libstagefright”代指Stagefright媒体库,用“stagefright”代指相应的bug。
虽然,多个Android版本的系统中都存在这个bug(接近1,000,000,000台设备),但是,很多人都认为这个漏洞无法被利用,主要是因为新版的Android实现了ASLR保护技术。
0x02 Metaphor
Metaphor代指的是我们对Stagefright的利用过程。在文中,我们详细的研究了libstagefright,并提出了一种可以绕过ASLR的新技术。和Google团队一样,我们利用了CVE20153864,因为相较于Joshua Drake发现的CVE20151538漏洞,这个漏洞更容易实现。
0x03 研究目标
我们之所以会持续研究这个媒体库,是因为其已经被证明了确实存在漏洞(bug和坏代码太多),受影响的设备成千上万,潜在的攻击途径也多种多样:mms(秘密进行),短信(自动进行),web浏览器(很少或几乎不需要用户交互)等等。
相比于前人的努力,我们希望实现一种更具普适性和可行性的利用方式,而可行性指的就是快速,可靠并且难以发现-理想情况下,只利用现有的漏洞。
总而言之,我们的目标是绕过ASLR。
0x04 MPEG-4文件
要想理解这个漏洞,首先要理解MPEG-4文件格式。还好不难:这种文件就是TLV(类型-长度-值TypeLengthValue)数据块的集合。在这种编码方式中,会有一个“type”值指定数据块类型,一个“length”值指定数据长度,一个“chunk”值指定数据本身。
以MPEG-4为例,首先编码“length”,然后是“type”,最后是“value”。下面的pseudo-C描述的就是MPEG-4的数据块格式:

当长度为0时,数据会一直持续到文件末尾。atom字段是一个短字符串(也叫作FourCC),描述的是数据块类型。
对于需要超过2^32个字节的类型,使用的格式也稍有不同:

在采用了树结构的类型中,子数据块存在于父数据块的数据中。
下图中描述了一个媒体文件:
Bug-CVE20153864
因为已经有很多文章都介绍过这个bug,所以这里就不多说了。我们使用了Android 5.1.0的源代码,如果有特殊情况,我们还会再做说明。
libstagefright中的这个bug出现在解析MPEG-4文件的过程中,或更具体的说,是解析tx3g atom字段,这个字段的作用是向媒体中嵌入字幕。
首先,我们看看这段代码的作用:

相当简单-这段代码会收集所有的字幕数据块,并将其附到一个长缓冲区中。
检查了size和chunk_size,并且在我们的控制下,允许我们在这里造成了一个整数缓冲区溢出:

要想实现堆溢出,我们需要至少一个合法的tx3g数据块,在整数溢出部分和堆溢出中都需要用到:

无论缓冲区实际分配的大小是多少,最终会导致data部分中的size字节被写到缓冲区中。
在构造堆时要注意,我们能够:
- 控制size-写入多少字节
- 控制data-写入多少数据
- 预测我们的对象会被分配到什么位置
- 分配的大小在我们的控制下
- Android使用了jemalloc作为其堆分配器(稍后再做说明)
考虑到这里,既然我们能够控制堆溢出的大小和数据,那么漏洞利用应该很容易实现。但是,实际中的限制很多,复杂化了漏洞的利用过程。
0x05 漏洞利用
在这一部分,我们介绍了漏洞的利用原理和限制,以及一些与漏洞利用相关的发现。
攻击途径
这个漏洞存在于媒体解析过程中,也就是说,受害者的设备甚至不需要播放媒体,而只需要解析即可。媒体解析过程是为了获取其元数据,比如视频长度,艺术家名称,标题,字幕,注释等等。
最后,我们选择的攻击途径是通过web浏览器,因为需要执行JavaScript,这样做的优缺点也很明显。可以使用下面的这些方法来诱使受害者访问我们的恶意网页:
- 攻击性网站-可以伪装成“在线观看全高清<最新电影>”
- 入侵合法网站-页面看似合法,但植入了隐藏内容(iframe,隐藏标签…)
- XSS-可信网站中植入恶意内容
- 广告-只存在于
<script>或<iframe>标签 - Drive-by攻击
- 免费WiFi-自动弹出web浏览器,打开含有恶意内容的门户
- 公交站上的二维码-在等公交车时,扫描下载游戏
下面的这些攻击途径不适用于我们的方法:
- WEB
- 广告-“合法”(或非合法)广告作为漏洞媒体
- 博客或论坛帖子-内嵌媒体
- MMS-自动获取和解析
- 已经在Android 5.1+上禁用
- 即时信息
- WhatsApp, Telegram, Viber, Skype, Facebook Messenger等
- 交友软件-攻击者介绍中存在漏洞媒体
受害者需要在攻击性网页上驻留一会儿。社会工程可能会增加这一漏洞的有效性-或其他针对受害者的长期攻击方法,比如更改主页。
将vtable重定向到堆
再次查看存在漏洞的代码:
最简单的利用方法是构建堆,这样的话,mDataSource对象会在缓冲区溢出后立刻被分配,然后利用这个bug,用我们的vtable(虚拟表)覆盖mDataSource的vtable,并设置对应的readAt入口点指向我们自己的内存。这就是exploit-38226的实现方式。
- 我们可以完全控制虚拟表-重定向任意方法到任意的代码地址
- 需要知道或猜测我们的虚假vtable地址-Google已经证明了这是可以预测的
- 要想找到ROP链Gadgets,需要知道libc.so函数的地址-即破解ASLR
Heap Shaping
要想更好地理解Metaphor,以及如何绕过ASLR,需要了解Android堆分配器-jemalloc的工作原理。
目前,你只需要知道jemalloc会将大小相似的对象分配到同一个run中。同一个run中会包含多个大小相同的缓冲区,这些缓冲区就叫做regions。稍小于region固定大小的对象会被向上舍入。
具体参见下图:

Heap Spraying
Heap Spraying是使用pssh atom完成的。当解析器遇到一个pssh数据块时,解析器会分配一个缓冲区,并将其附到一个缓冲区列表中:

我们控制其大小,我们就可以提供较大的值。这种方法的局限性在于,媒体文件中必须要有相应大小的数据,不过接下来我们会说明如何克服这一限制。
Heap Grooming
Heap Grooming不同于Heap Spraying简单地分配大量的对象。通过控制分配和释放顺序,我们可以采用一种可预见的方式来设计堆对象的顺序。在exploit-38226中,这是利用avcC和hvcC数据块实现的:
(hvcC基本上是一致的)
解析器分配一个可控大小的缓冲区,然后将其传递给MetaData::setData。MetaData::setData会将数据复制到一个新的缓冲区,然后删除先前的缓冲区,当然其大小也在我们的控制下。
这种方法不一定能在所有设备上应用,或许是因为jemalloc的配置不同,并且需要分配两个大小相同的缓冲区-其中一个是MPEG4Extractor::p arse3GPPMetaData中的临时缓冲区,另一个用于内部的MetaData对象。
一种更具普适性的Heap Grooming方法是使用MPEG-4 atoms,pref,auth和gnre。这些字段都是在MPEG4Extractor::parse3GPPMetaData: 的内部进行解析:

MetaData::setCString复制了一个从缓冲区+6开始的空终止(null-terminated)字符串:

我们可以通过chunk_size控制临时缓冲区的大小,通过null字节的位置来控制实际复制哪个缓冲区,这样我们就可以将临时对象分配到另一个的run中,并提高漏洞利用的灵活性。
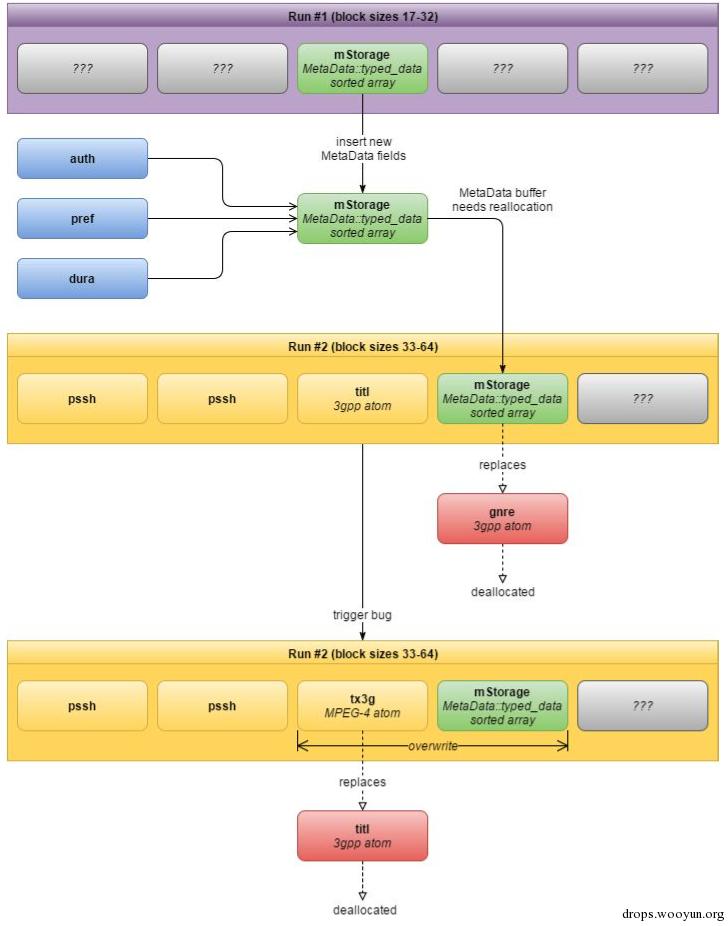
注意,一旦我们向MetaData中添加一个已有的项目,旧项目就会被替换。前面提到的MPEG-4 atoms为我们提供了4个相同的基元素(primitives)用于对堆进行控制。
为了覆盖mDataSource,我们需要将其移动到堆底的一个位置,在这个位置上我们就可以预测到堆的位置。这一过程和exploit-38226一样,都使用了stbl atom来重新分配mDataSource:
注意,stbl atom分配了一个新的MPEG4DataSource-因为我们的攻击途径是通过web浏览器,所以,mDataSource的类型是NuCachedSource2,NuCachedSource2::flags是:

下图中描述的是通过Heap Grooming让堆溢出mDataSource的过程:
ssh atoms用于Heap Spraying,这样新的堆就会按照预定顺序运行。然后,使用titl和gnre atoms作为占位符-首先分配titl,然后分配gnre,释放了gnre后,我们再使用stbl atom分配一个MPEG4DataSource。
当我们释放了titl后,这个数据块就会被释放,因为在下一次分配时,tx3g atom会替代其位置。
ROP链Gadgets
我们稍微修改了谷歌在exploit-38226中提出的ROP链。例如,mmap和memcpy被用于了分配shellcode-而实际上,已经有一个缓冲区的地址是已知的了:

我们可以简单地用mprotect来替换这两个gadgets。
(注意,并不是所有设备上都是这一个地址)
Google使用了很复杂的gadgets从栈中弹出大量不必要的参数,导致复杂化了ROP链。而我们只是简单地使用了pop {pc} 和pop {r0, r1, r2, pc} 指令。
和Google Project Zero: Stagefrightened一样,我们使用了相同的stack pivot gadget:
“这样可以加载大部分寄存器,包括在r0上的栈指针,这个指针指向了我们控制的数据。此时,可以很简单地通过利用ROP链来分配RWX内存,将其复制到shellcode中,然后使用libc.so中的函数和gadgets来跳转。”(Google Project Zero)
我们的远程代码执行漏洞需要知道下面的四个地址:
-
Call void函数:
pop{pc}
-
最多有3个参数的Call 函数:
pop{r0,r1,r2,pc}
-
替换栈并调用shellcode:
add r2,r0,#76;0x4c
ldm r2,{r4,r5,r6,r7,r8,r9,r10,r11,r12,sp,lr}
...
...
bx lr
-
使用mprotect将一个区域标记为可执行,然后返回:
...
...
bx lr
我们已经知道了mDataSource的确切大小-在溢出时,其类型是MPEG4DataSource:

IDA中显示,readAt在vtable中的偏移是7:
readAt在字节中的偏移是:

在所有测试过的设备中,MPEG4DataSource的大小和readAt的偏移都是相同的。
最后的ROP链在栈中看起来是这样的,从中可以看出是哪个寄存器复制了该项目:

其他的代码指定漏洞都类似于exploit-38226。
破解ASLR
破解ASLR需要一些设备信息,因为不同的设备会使用不同的配置-可能会修改一些偏移位置或可预测的地址位置。
利用同一个漏洞,也可能获取到任意的指针读取,导致web浏览器泄露,从而收集破解ASLR需要的信息。但是,我们读取内存的能力有限,因为这个漏洞存在诸多限制。
JavaScript的功能
因为是通过web浏览器来攻击,所以我们假设能够执行JavaScript。编码在媒体文件中的元数据可以通过JavaScript使用某些<video>标签属性来访问,比如videoWidth,videoHeight和duration。
我们可以利用堆溢出漏洞用一个指针覆盖这个元数据到任意的内存位置,这样,任意的内存都可以被发送回浏览器,然后通过JavaScript读取。
返回元数据
所有的元数据都储存在MetaData类中。这类媒体具有自己的元数据,叫做mFileMetaData:

并且每个Track都有自己的meta字段:
只有把mInitCheck设置为OK,元数据才可以返回到浏览器:
只有在解析moov atom时,才可以设置mInitCheck:
今早将“moov”数据块整合到媒体文件中,能够保证元数据可以返回到web浏览器。
注意:这种方法不适用于Android 4.4.4及更低版本。这些版本上的代码似乎只会接收包含整个文件部分的moov数据块。否则,只要“moov”数据块结束,则会返回NKNOWN_ERROR,因为缺少DRM内容,MPEG4的“sidx”和“moof” atoms都会终止解析:
所以,这种方法只能适用于Android 5.0-5.1。
溢出后返回元数据
我们无法重复使用同一个媒体文件来执行多次溢出-在触发了tx3g bug后,无法避免ERROR_IO从MPEG4Extractor::parseChunk返回:
返回值会转换成size_t(32位)并与chunk_size(对比)对比-要想实现整数溢出,这个值要远远大于2^32。
MPEG4Extractor::parseChunk会接收一个数据块offset和数据块depth。这种方法可以解析数据块并处理超前偏移。

对于某些MPEG-4 atoms,还会递归解析内部的数据块。如果解析成功,偏移会前进到数据块末尾。
在使用较大的值造成溢出后,我们从tx3g解析返回到这里:
我们得到了:


所以,如果返回了ERROR_IO,所有的解析都会停止:
也就是说,我们无法使用同一个媒体文件来执行多次溢出。
绕过进程终止
在使用HTTP来处理视频流时,mDataSource的类型是NuCachedSource2.mDataSource>readAt指定的NuCachedSource2::readAt会触发调用NuCachedSource2::readInternal,如果size过大,mediaserver就会被终止:

在失败时,CHECK_LE会终止进程,因为要想利用成功,size的值需要很大,每当我们尝试利用bug时,NuCachedSource2::readInternal检查总是会失败。
要想避免进程终止,我们需要绕过NuCachedSource2::readInternal调用。通过使用XMLHttpRequest和responseType=‘blob’从JavaScript加载媒体,浏览器会把视频缓存到文件系统。使用URL.createObjectURL,我们可以这样来引用缓存文件:


URL.createObjectURL函数会创建一个URL来引用xhr.response中的data数据块。
下面是一个对象URL示例:
当Chrome 尝试读取“ blob” URLs时,实际是作为本地资源访问。我们可以看到Chrome缓存中的文件:(“ls -a”显示隐藏文件)
mediaserver中确实有一个描述符指向了这里:(“ls -l”后是链接)

因为这个URL指向了文件系统,mediaserver把数据来源(在我们这里是mDataSource)设置到了一个FileSource类的对象,而不是NuCachedSource2 类。这两个类之间有差别,NuCachedSource2处理的是HTTP流和在线媒体缓存,而FileSource能够在本地文件上执行查找和读取操作。 FileSource::readAt 并没有使用任何CHECK_xx宏-也就是说我们绕过了进程终止的问题。
泄露信息
我们前面提到过,mediaserver会解析媒体文件中的元数据并将其发送给web浏览器。元数据储存在MetaData对象中,所有的数据都储存在MetaData对象的mltems字段中,这些字段实际上是MetaData::typed_data值所对应的FourCC(4字符代码)秘钥:

typed_data也在同一个文件中:

如果mSize大于4,ext_data会指向内存中储存数据的位置。否则,数据会储存在储存器中。注意,这两者是一个并集,也就是说,ext_data和储存器共用同一个地址。
KeyedVector对象的数据储存在mStorage字段中(由VectorImpl类继承):

mStorage的内容是一系列的秘钥和MetaData::typed_data 元素。在GDB中看起来是这样的:
例如:

通过覆盖mStorage的内容,我们可以覆盖元数据指针,从而指向内存中的任意位置,这样,信息就可以泄露给web浏览器!
注意,只要size大于4,就是一个指针,但是我们可以控制size的大小-我们可以将元数据字段的大小设置为4或更小,避免不必要的元数据字段使用指针。即使是强制的mime型字段,我们也可以将其设置成一个size不大于4的空终止字符串(null-terminated)。
因为mSize必须大于4,我们只能通过duration字段来实现内存泄露-因为duration是8字节长度,所以也是一个指针。videoWidth和videoHeight字段只有4字节,所以无法用来泄露内存。如果把这些字段设置大于4,那么就会导致进程终止。
KeyedVector<key, value>使用SortedVector<key_value_pair_t<key,value>>储存其数据。当一个新的值添加到KeyedVector时,这个值会被插入到排序向量,这样,元素顺序仍然会根据秘钥排序。
下面是一些原始的KeyedVector数据,来自一个具有多组元数据的媒体文件,其顺序就是按照秘钥排序:

我们需要在崩溃之前,知道插入了多少个元数据元素。这点做起来不难,因为我们控制了媒体文件,也就能预测其状态。在覆盖元素时,不需要使用相同类型的元素,只需要保证元素顺序是根据秘钥来排序(如上)。
总的来说,我们需要用排序元素覆盖一些16字节的机构。
这些元素的类型是:
如上所示。
Heap Grooming也是采用类似的方式完成的,使用相同的MPEG-4 atoms(itl,gnre,auth,pref)溢出mDataSource;并利用同一个堆溢出漏洞CVE20153864来实现覆盖。
在元数据返回给浏览器之前,duration最终会作为字符串返回。下面是最长的duration字段:

最终,其时长从百分之一秒转换成了千分之一秒,会造成数据丢失。接着,我们就可以把一个8字节的整数泄露给浏览器,准确率在±500。
值得注意的是浏览器过滤的最高位会设置为负值,无穷大或NaNs(这些数值还有很多表示方式)。这些值会被忽略掉,而duration字段会设置为0。
注意,PRId64 是一个有签名的64位整数。考虑到整个转换过程,可能的最大有效值是:

更高的值会溢出到签名位,而浏览器则会过滤到这个值,因为负值长度(无穷大/NaN)是没有意义的。
只要23个最高位填充的都是0,并且由于向上舍入到1000,造成了几个位的丢失,我们最终可以泄露8个字节。而根据这个值,我们能获取到32~35个可用的位。
ASLR的弱点
32位ARM Linux系统上的ASLR算法很简单-ASLR会将所有的模块随机向下移动几页,范围在0~255页。移动的页面数量叫做ASLR slide,这个值是在进程启动是生成的,并且会持续整个进程周期。

然后,这个值会被传递到mmap_base:

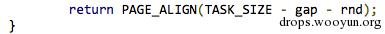
每个模块都会加载到其首选基址,然后再按照ASLR slide移动。为了进行验证,我们运行了mediaserver上百次-记录下了所有模块的可能地址范围。与ASLR随机化一致,总共的地址范围有256页,与其他模块的距离保持不变。所以说,所有模块的ASLR slide都是一样的。
因为所有模块都使用同一个ASLR slide,我们只需要知道一个模块的基址就能够知道所有其他模块的内存布局,和上面提到的一样,只有256个选项。
我们可以使用先前创建的设备版本查询表来获取gadget的偏移。只要我们知道了一个模块的基址,我们就能够把这些gadget偏移翻译成绝对地址。
设备指纹
比较方便的是,所有必须的gadget都贮存在libc.so中。由于不同设备使用不同版本的libc.so,所以gadget偏移也会变化。但是,在很多情况下,你可以只根据User-Agent HTTP标头来获取设备指纹-因为标头中可能会有设备创建版本和Android版本。
通过构建设备版本查询表来获取gadget偏移,我们省去了执行一些高成本操作的需要。最后,要想执行远程代码,还需要先知道libc.so在运行时的基址。
查找libc.so
通过研究/proc/pid/maps,我们发现模块位置基本上是可以预测的,其最大距离是256页。假设,有一个可读内存部分大于256页(1MB),我们可以确定模块的首选基址可能的最大偏移是255页。
下图是对这种概念的解释:

libicui18n.so模块能够运行,因为其代码部分是可读的,并且大于1MB:

注意,有些模块的相邻部分(例如,text,data)之间有保护页面,但是,我们只需要足够大的连续内存区域。在这种情况下,text部分就足够大了,因为其大小有1,388页。
ASLR slide是模块首选基址和运行时基址之间的距离:

所以:

(注意,ASLR向下移动)
我们知道ELF标头必须是页面对其,很奇怪的是,ELF标头位于可执行部分的开头:

从首选基址开始,每次向下移动一页,我们最后停在了ELF标头上。但是,我们无法泄露ELF标头,因为这种方法的最大限制就是8字节。ELF标头的前8个字节是:
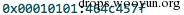
下面是泄露限制,最大不超过:
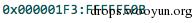
其中有一个字段很特殊,因为这个字段的最高位总是0,所以我们可以泄露这个字段-位于偏移0x88上,第三个程序标头表的p_memsz和p_flags:
ELF标头的0x34字节+前两个程序标头表的0x20字节+字段偏移的0x14字节。

下图中显示的是ELF文件格式和感兴趣的字段:
第三个程序标头表中的memsz(p_memsz) 字段符合我们的标准-可读,模块是唯一的,位置固定。
下面的命令可以转储ELF标头值,这样我们就能够找到前面提到的值了:
(注意,这个8字节值同样有p_flags,但是,这个值看起来很小,不会超过最大值限制)
现在,我们可以创建一个libicui8n.so p_memsz字段查询表,每个设备对应一个项目。
通过这种方法,每当受害者解析一个媒体文件时,一些信息就会通过这些字段泄露。要想找到ELF标头,修复gadget偏移到绝对地址,受害者必须要下载和解析256个媒体文件。由于heap spray,用于执行代码的媒体文件可能会比较大才能让heap spray落在预测地址-大约32MB或更大。
HTTP支持GZIP压缩的内容。对于一个32MB的媒体文件而言,其中大多数填充是0,我们总共可以得到33kB的网络流量-小了接近1000倍-这样漏洞利用才能够可行。
0x06 汇总
我们的漏洞由几个模块组成,用于实现自动化和实时生成漏洞。这些模块包括:
- Crash
生成小的通用媒体文件
造成mediaserver崩溃,从而重置其状态
在自动测试和创建查询表时,检查是否存在漏洞
- RCE
根据特定的设备,生成一个媒体文件,用于在mediaserver中执行shellcode
查询表提供了gadget偏移和libc.so首选基址
接收运行时的ASLR slide作为一个参数,并将gadget偏移翻译成绝对地址
- Leak
根据特定设备,生成一个媒体文件,用于从mediaserver进程中泄露内存
接收一个地址作为参数,从这个地址中泄露数据-这个地址可以是ummapped或保护页面-导致崩溃
需要通过<video>标签的duration字段返回信息
需要web浏览器支持blob响应类型的XmlHttpRequest
旧版浏览器不支持
从Chrome19开始支持
三星SBrowser基于Chromium-最早版本基于Chromium 18
与ROM关系不大,旧版浏览器可能没有实现ASLR
下面是完整的漏洞利用流程:
0x07 最后要求
本文中提出的这些方法都需要提前了解受害者的设备。即使能观察到受害者的User-Agent标头,但是,仅仅凭借这一点也无法了解关键的设备信息,比如gadget偏移或可预测地址。
查询表使用了设备创建版本来查找漏洞利用所需要的相关信息。要想创建查询表,你需要:
- libc.so
提取首选基址
提取4个必要gadget(在ROP Chain Gadgets 章节提到过)
pop {pc}
pop {r0,r1,r2,pc}
stack pivot gadget地址
mprotect地址
- libicui8n.so
提取首选基址
计算与libc.so之间的距离
ELF标头模块标示符
- jemalloc 配置
jemalloc区域的大小
可以从libc.so提取
可以在设备上运行测试程序来获取这些值
- 可预测的heap spray地址
不同设备上的最优heap spray地址是不同的,在现实中,不同设备可能使用同一个地址
最佳选择是多次测试设备
通过进一步的研究,有可能可以不使用查询表,从而让漏洞利用更有普适性。
注意,要想找到某些值,最好通过真实的设备来获取。libc.so和libicui8n.so模块,以及jemalloc配置都可以从ROM的系统镜像中提取,而可以猜测可预测的heap spray地址-但是对于某些设备来说,这不是最佳做法。
0x08 总结
这次研究证明了这个漏洞是可以被利用的。但是,首先要提前了解相关的设备信息,因为需要根据不同的ROM构建查询表。
我们的漏洞在使用旧版ROM的Nexus 5上发挥最好。另外,我们还测试了HTC One,LG G3和Samsung S5,但是,在针对不同的厂商时,漏洞利用也稍有不同,需要作出一些修改。
很重要的一点是,这是一个远程代码执行漏洞,可能还需要提升mediaserver进程的权限,因为不同的厂商会赋予mediaserver不同的权限(参考/init.rc)。
通过libicui8n.so模块实现利用时,利用时间最少几秒钟,最多2分钟。
在下一章节,我们提出了一种更复杂的方法,这种方法能够减少利用时间-差不多下降了4倍。
注意:
- 23.5%的安卓设备运行着Adroid 5.0-5.1-大约235,000,000 台设备
- 4.0%的安卓设备运行着没有ASLR的Adroid 2.x-大约40,000,000 台设备
但是旧设备上已经存在了大量的漏洞
通过观察这些数字,很难确定有多少台设备是面临威胁的。
这些数字中包括了大量的Android平板,TV和手表,但是,所有这些设备上都存在这些漏洞。
0x09 彩蛋
提升Heap Spray的效果
在exploit-38226中,通过使用stbl atom来封装spray数据,可以成倍加强heap spray的效果。在NCC Group文章中,也提到了进一步改善其效果的方法。利用这种方法,可以大幅缩小远程代码执行漏洞的体积。
减少利用耗时
通过从ELF标头中泄露不同的信息,可以从很大程度上减少需要的泄露次数。除了泄露ELF标头,我们可以从任意一个包含多个模块的内存区域中选择任意一个地址来泄露。
下面的例子是一个728页的内存区域,包含有24个ELF标头,只有5个不可访问的漏洞。

(在不同设备上,这些值也是不同的-这里只是一个例子)
我们可以从这个区域中随机选择地址:
- 只有5个漏洞-在解析每个媒体文件时,只有0.69%的概率会导致崩溃
- 我们能够识别57页-在解析每个媒体文件时,有7.83%的概率能找到ASLR slide
对比来看,如果靠猜测的话,要想从256页中猜到正确的ASLR,只有0.39%的概率。
在这种方法下,利用耗时在250毫秒和30秒之间,平均5到10秒,取决于标示符数量,不同的设备,运行负担,网络稳定性,最重要是尝试的泄露次数。
0x0A 研究建议
这里提到的信息泄露方法无法应用在SBrowser-这一浏览器似乎能阻止响应类型是blob的XmlHttpRequest对象加载视频;我们不清楚这是一种安全机制,还是浏览器不支持这种功能。
你可以绕过NuCachedSource2::readInternal method CHECK_LE macro:

通过x-cache-config HTTP 标头来提供比较大的HighwaterThresholdBytes 值:

要想利用Android 4.4.4上的泄露方法,需要研究DRM内容。