前言:那天我正在开发网站最关键的部分——XSS过滤器,女神突然来电话说:“那东西好难呀,别开发了,来我家玩吧!”。我“啪”地一下把电话挂了,想让我的网站出XSS漏洞,没门~
python做web开发当今已经逐渐成为主流之一,但相关的一些第三方模块和库还没有php和node.js多。
比如XSS过滤组件,PHP下有著名的“HTML Purifier”(http://htmlpurifier.org/ ),还有非著名过滤组件“XssHtml”(http://phith0n.github.io/XssHtml ),当然后者是我自己开发的。
python的pip下也可以安装一款名为“html-purifier”的库,但此purifier和php下的就大不相同了。这个库负责将html中,白名单以外的标签和属性过滤掉。
注意,他并不是过滤XSS的,只是过滤不在白名单内的标签和属性。也就是说,类似<a href="javascript:xxx">等javascript是不会被过滤的。
所以我只好自己开发了一个python xss filter,用在自己以后做的python项目中。
说一下具体实现原理。
一、解析HTML
解析HTML,使用的是python自带的HTMLParser类。在python2中,名字叫HTMLParser,在python3中叫html.parser。
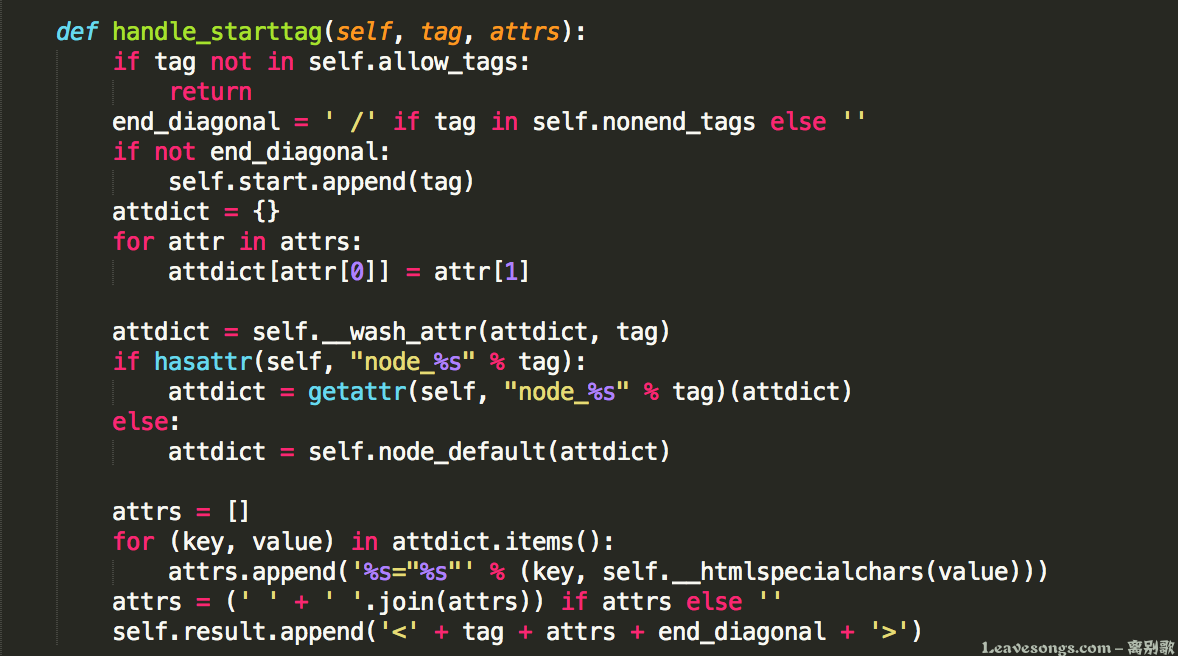
使用HTMLParser,需要自己的类继承HTMLParser,并实现其中的handle_starttag、handle_startendtag、handle_endtag、handle_data等方法。
如handle_starttag方法,是在进入一个标签的时候被调用的。我们就可以在实现这个方法的时候,就可以获得此时正在处理的标签tag,和所有属性attrs。
我们就可以检查tag、attrs是否在白名单中,并对其中特殊的一些标签和属性做特殊处理,如下:
二、链接特殊处理
有些属性是可以用javascript伪协议来执行javascript代码的,如a的href,embed的src,所以需要对其进行特殊处理:判断是否以http|https|ftp://开头,如果不是则强制在前面加上http://
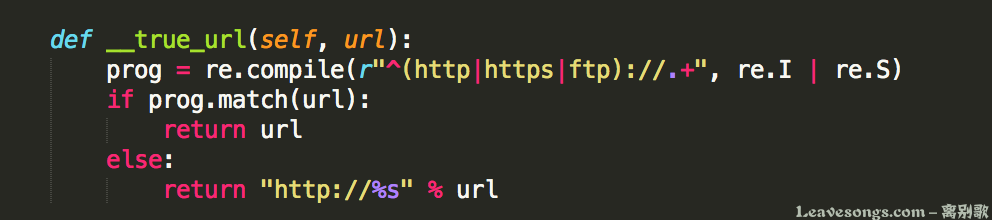
通过这个方式,对抗潜在的XSS注入。
三、embed特殊处理
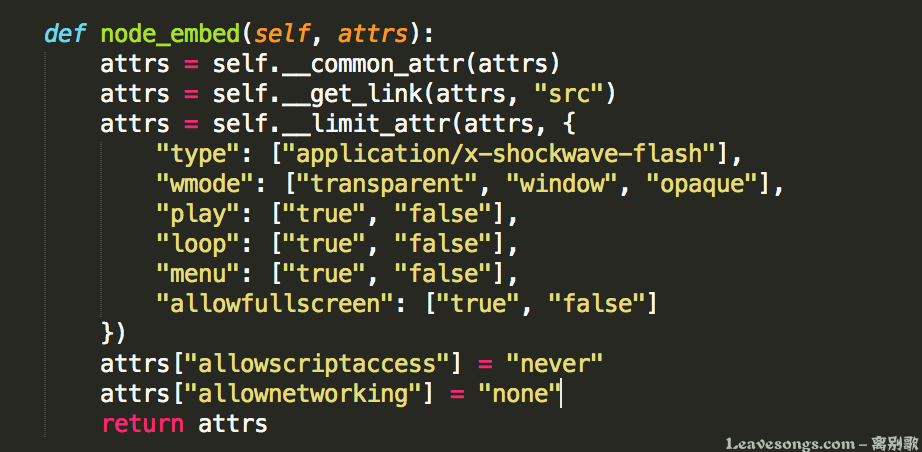
embed是嵌入swf等媒体文件的标签,理论上有时候我们的富文本编辑器是允许插入flash的。但我们需要保证flash内不能执行任意javascript代码,也不能让他发出一些HTTP请求(容易造成CSRF攻击)。
所以强制设置embed标签的allowscriptaccess=never,allownetworking=none:
四、拼接标签和属性的时候,防止双引号越出,成为新标签
我曾经在Roundcube Webmail中找到一个XSS漏洞(CVE-2015-1433),导致原因就是因为白名单检测完毕后再拼接html标签和属性的时候没有过滤双引号,导致属性值越出,变成一个新的属性名,导致XSS。
所以我这里使用self.__htmlspecialchars处理属性值,防止越出:

最后,这个模块使用也比较方便,最简单的demo如下:
import pxfilter parser = pxfilter.XssHtml() parser.feed('<html code>') parser.close() html = parser.getHtml() print html
再根据源码中的说明进行修改即可。github项目地址:https://github.com/phith0n/python-xss-filter
自己用web.py搭了个demo,欢迎测试、提交issues:http://python-xss-filter.leavesongs.com/ ,功能上、安全上都还需要大家给些建议。