0x00 前言
这个系列教程我本来打算的是翻译,后来过了一下文章发现教学过程不是很友好,所以大体是按他的思路,不过其中做了很多改动,还有个事情就是我假定读者已经了解基础的python和SQL注入的知识。还有一个需要注意的是我是写在ipython notebook中,所以文中的代码可能需要一点改动才能用。
我觉得这篇文章的简要的主题就是,给"如何识别sql注入" 提供一种思路,这个思路的本身就是用数据科学的形式来解决问题,其实就是所谓的机器学习。
为了达到我们的目标就需要一个过程:
- 收集数据
- 思考数据
- 特征工程
- 机器学习
0x01 准备
1. tools
这个系列主要以python为主,所以下面的是所需的python库,我不会教你怎么安装这些东西。
sqlparse (一个用于解析sql语法树的库) Scikit-Learn (python机器学习库) Pandas (用于快速处理一定量的数据) numpy (用于科学计算) matplotlib (用于数据可视化)
2. 什么是机器学习?
因为本文中用的是监督学习,那么我们会注入监督学习所需要的知识,机器学习顾名思义就是让机器具备学习的能力,假设我们已经有了一个算法能够进行学习,那么我们该如何教给它知识,假设一个小孩,我们需要让它知道如何辨认水果,我们就会放两堆不同的水果,告诉他左边的是苹果,右边的是香蕉。然后等到他学习了这堆狗屎玩意,我们就可以带着他去看一堆新的水果让后让他自己进行辨认了。 换句话说我们这次就是要准备一堆的数据,告诉算法,左边的是正常的sql请求,右边的是sql注入的请求,让后让他进行学习,最后我们再给他一堆未知的数据进行测试。
3. SQL语法树
你觉得sql语言从输入数据库到放回内容都经过了怎样的处理,sql语言是一种DSL(领域特定语言),比如ruby,c,java,这些可以做任何事,但有一些语言只能做某个领域的事,sql就是这样一种语言,它只能描述对于数据的操作。但是它在大归类的时候是被归类到编程语言里的,就需要经过词法分析再到语法分析,对于这个过程不了解的同学可以看。 http://zone.wooyun.org/content/17006
0x02 准备数据
因为这次的数据已经准备好了,所以我们所需要就是写个小脚本把他读取出来,所需要的东西我会进行打包。
下载地址:下载
# -*- coding: utf-8 -*-
import os
import pandas as pd
basedir = '/Users/slay/project/python/datahack/data_hacking/sql_injection/data'
filelist = os.listdir(basedir)
df_list = []
# 循环读取 basedir下面的内容,文件名为 'legit'的是合法内容,malicious的是 恶意sql语句
for file in filelist:
df = pd.read_csv(os.path.join(basedir,file), sep='|||', names=['raw_sql'], header=None)
df['type'] = 'legit' if file.split('.')[0] == 'legit' else 'malicious'
df_list.append(df)
# 将内容放入 dataframe对象
dataframe = pd.concat(df_list, ignore_index=True)
dataframe.dropna(inplace=True)
# 统计内容
print dataframe['type'].value_counts()
# 查看前五个
dataframe.head()

我们现在可以清楚的知道我们面临的是一堆什么样的数据了。
0x03 特征工程
1. 概念
So,然后呢?我们是不是就可以把数据丢进算法里然后得到一个高大上的sql防火墙了?那么我们现在来想一个问题,我们有两个sql语句,从admin表中查看*的内容。
select user from admin;
select hello from admin;
算法最后得到的输入是什么,是[1,1,0,1,1] 和 [1,0,1,1,1] 没看懂没关系,就是说得到了这样的东西。
{select:1, user:1, hello:0, from:1, admin:1} {select:1, user:0, hello:1, from:1, admin:1}
是不是哪里不对,就是说在机器看来 user 和 hello 在本质来看是属于不同的类型的玩意,但是对于了解sql语言本身的你知道他们是一样的东西,所以我们就需要给同一种东西打一个标签让机器能够知道。
那么是否对什么是特征工程有了一些模糊的了解?要做好特征工程,就需要对于你所面临的问题有着深刻的了解,就是“领域知识”,带入这个问题就像你对于sql语言的了解,在这个了解的基础上去处理特征,让算法更能将其分类。带入水果分类问题就是,你得告诉小孩,香蕉是长长的,黄色的,苹果是红色的,圆圆的,当然,如果你直接把上面的玩意丢进算法里头,分类器也是可以工作的,准确度大概能过 70%,也许你看起来还行,当是我只能告诉你这是个灾难。这让我想起某次数据挖掘的竞赛,第一名和第一千名的分差是0.01,这群变态。
2. 转化数据
所以现在我们需要的就是将原始数据转化成特征,这就是为什么我刚才说到语法树的,我们需要对sql语句进行处理,对同一种类型的东西给予同一种标示,现在我们使用sqlparse 模块建立一个函数来处理sql语句。
import sqlparse
import string
def parse_sql(raw_sql):
parsed_sql = []
sql = sqlparse.parse(unicode(raw_sql,'utf-8'))
for parse in sql:
for token in parse.tokens:
if token._get_repr_name() != 'Whitespace':
parsed_sql.append(token._get_repr_name())
return parsed_sql
sql_one = parse_sql("select 2 from admin")
sql_two = parse_sql("INSERT INTO Persons VALUES ('Gates', 'Bill', 'Xuanwumen 10', 'Beijing')")
print "sql one :%s"%(sql_one)
print "sql two :%s"%(sql_two)
输出 sql one :['DML', 'Integer', 'Keyword', 'Keyword'] sql two :['DML', 'Keyword', 'Identifier', 'Keyword', 'Parenthesis']
我们可以看到 select 和 insert都被认定为 dml,那么现在我们要做的就是观测数据,就是查看特征是否拥有将数据分类的能力,现在我们先对sql语句进行转换。
dataframe['parsed_sql'] = dataframe['raw_sql'].map(lambda x:parse_sql(x))
dataframe.head()
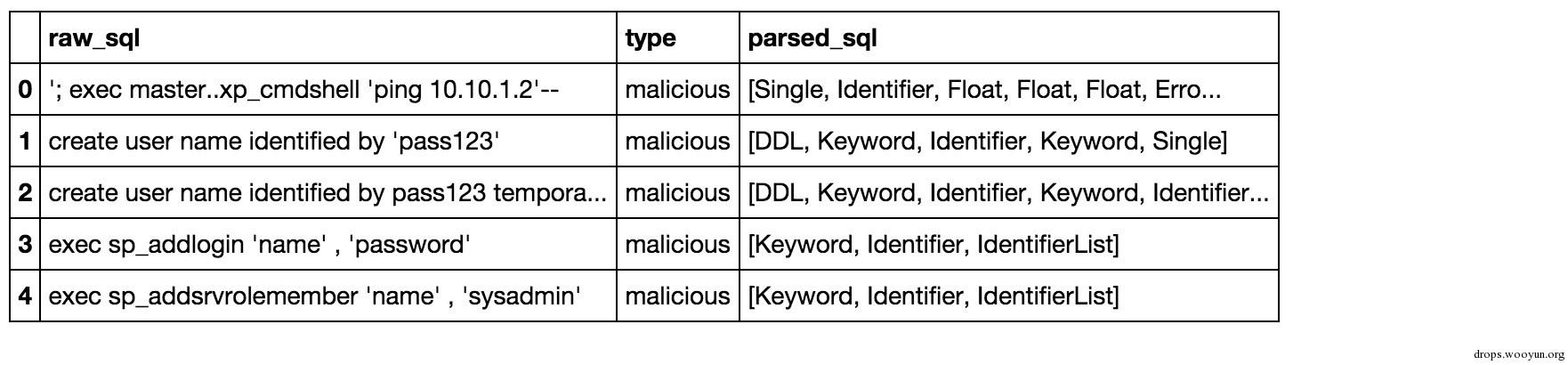
3. Other
理论上我们现在就可以直接把这些东西扔进算法中,不过为了方便我在说点别的,分类器的性能很大程度上取决于特征,假设这些无法很好的对数据进行分类,那我们就需要考虑对特征进行一些别的处理,比如你觉得sql注入的话sql语句貌似都比较长,那么可以将其转化成特征。
dataframe['len'] = dataframe['parsed_sql'].map(lambda x:len(x))
dataframe.head()
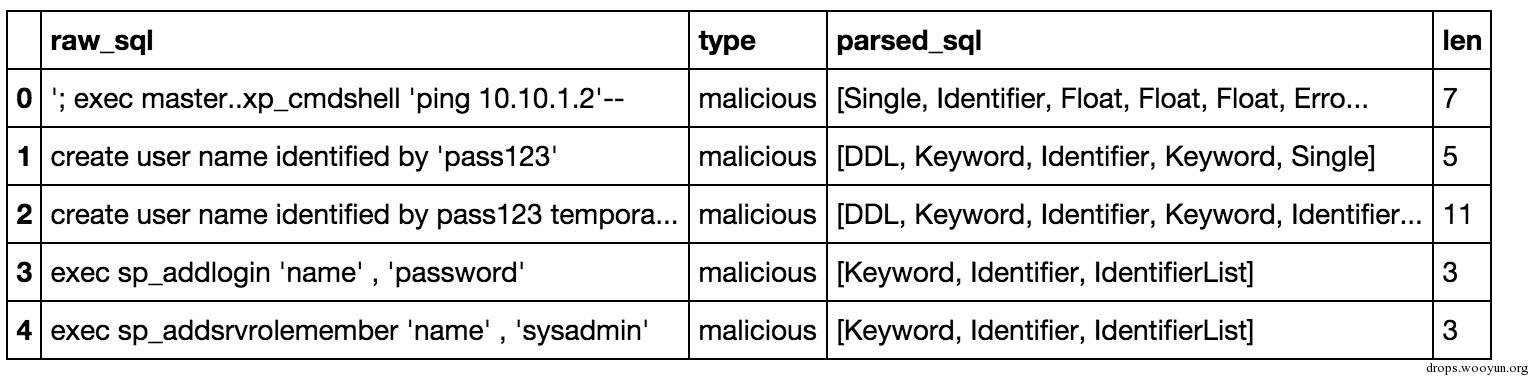
现在我们需要观测下数据,看看长度是否有将数据进行分类的能力。
%matplotlib inline
import matplotlib.pyplot as plt
dataframe.boxplot('len','type')
plt.ylabel('SQL Statement Length')
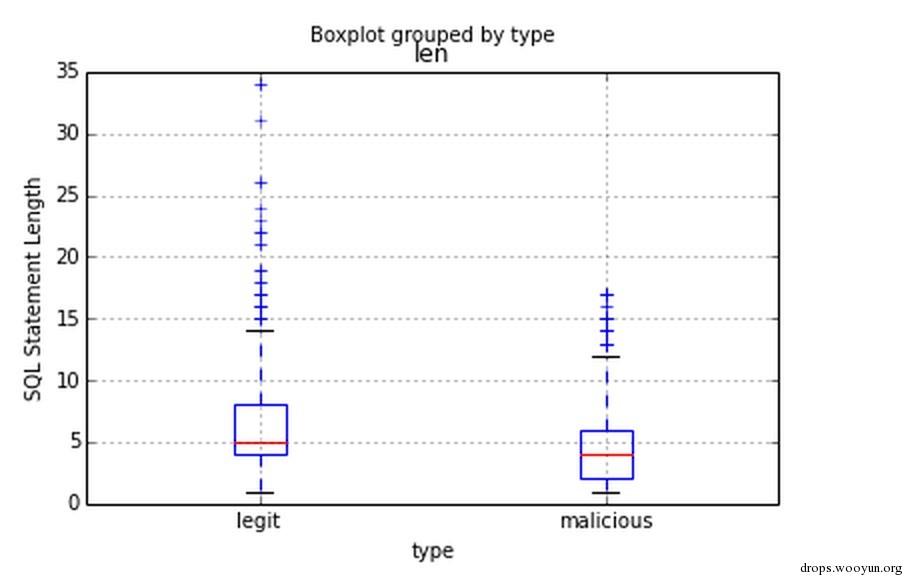
0x04 机器学习
1. Train & Test
这里我就直接调用python库了,因为解释起来很麻烦,而且就我对于这次要使用的随机森林(Random Forest)的了解层度,我觉得还不如不讲,对于其数学原理有兴趣的可以参考下面的paper,是我见过对随机森林解释的最清楚的。
Gilles Louppe《随机森林:从理论到实践》 http://arxiv.org/pdf/1407.7502v1.pdf
接下来我们再对特征做一次处理,转换成0和1的向量形式,x是我们的特征数据,y表示结果。
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_extraction.text import CountVectorizer
import string
vectorizer = CountVectorizer(min_df=1)
le = LabelEncoder()
X = vectorizer.fit_transform(dataframe['parsed_sql'].map(lambda x:string.join(x,' ')))
x_len = dataframe.as_matrix(['len']).reshape(X.shape[0],1)
x = X.toarray()
y = le.fit_transform(dataframe['type'].tolist())
print x[:100]
print y[:100]
输出
[[0 0 0 ..., 2 0 0]
[0 0 0 ..., 1 0 0]
[0 0 0 ..., 0 0 0]
...,
[0 0 0 ..., 0 0 0]
[0 0 0 ..., 0 0 0]
[0 0 0 ..., 0 0 0]]
[1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
输入
clf = sklearn.ensemble.RandomForestClassifier(n_estimators=30)
scores = sklearn.cross_validation.cross_val_score(clf, x, y, cv=10, n_jobs=4)
print scores
输出
[ 0.97699497 0.99928109 0.99928058 1. 1. 0.97192225
0.99928006 0.99856012 1. 1. ]
上面的cross_validation是我们测试分类器的一种方法,原理就是把训练后的分类器在一些分割后的数据集上测试结果,从得出的多个评分中可以更好的评估性能,我们得出了一个貌似不错的结果,接下来让我们训练分类器
from sklearn.cross_validation import train_test_split
# 将数据分割为 训练数据 和 测试数据,训练数据用于训练模型,测试数据用于测试分类器性能。
X_train, X_test, y_train, y_test, index_train, index_test = train_test_split(x, y, dataframe.index, test_size=0.2)
# 开始训练
clf.fit(X_train, y_train)
# 预测
X_pred = clf.predict(X_test)
如果刚才那些数值无法直观的看出你训练了个什么玩意出来,那么你就需要一个混淆矩阵。
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(X_pred,y_test)
print cm
# Show confusion matrix in a separate window
plt.matshow(cm)
plt.title('Confusion matrix')
plt.colorbar()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
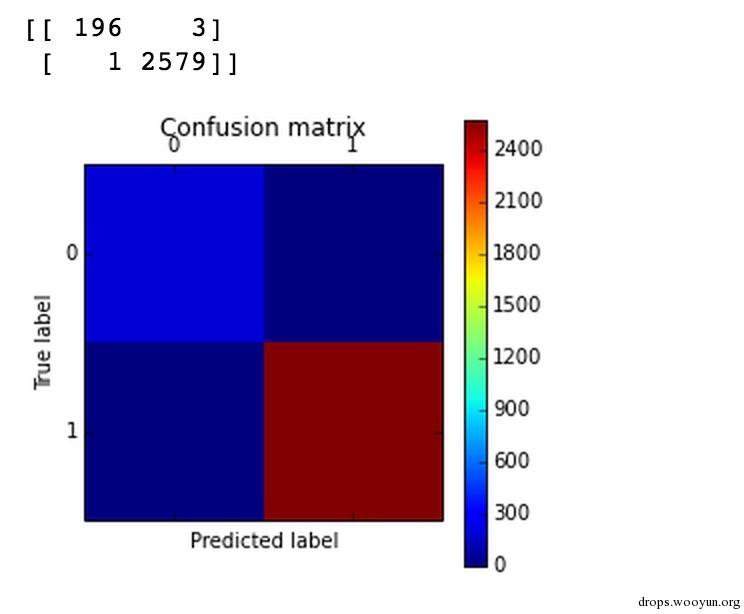
混淆矩阵可以更加直观的让我们观察数据,我们的数据氛围 0,1两类,比如 [0,0]=196 就是legit被正确分类的样本,[0,1]=3是被错误分类的样本,那么第二行就是恶意样本分类的情况。
现在我们看起来分类起似乎工作的不错,达到了99%的正确率,可是你想象这个问题,每199个正确样本就有3个被错误分类,一般来说一个中型的网站需要处理的sql语句就可能会达到 上面的1000倍,就是说你可能会有3000个无害的语句被拦截。所以下面我们需要的是降低legit被错误分类的概率。
2. 调整
sklearn大部分的模型有个功能叫predict_proba,就是说预测的概率,predict其实就是内部调用下predict_proba,然后按50%。我们可以装变一下直接调用predict_proba,让我们自己调整分类的概率。
loss = np.zeros(2)
y_probs = clf.predict_proba(X_test)[:,1]
thres = 0.7 # 用0.7的几率来分类
y_pro = np.zeros(y_probs.shape)
y_pro[y_probs>thres]=1.
cm = confusion_matrix(y_test, y_pro)
print cm
输出
[[ 197 0]
[ 5 2577]]
legit被错误分类的概率降低了,但是0.7只是我们随意想出来的一个参数,能不能简单的想个办法优化一下呢?让我们简单定义一个函数f(x),会随着我们输入的参数输出误分类的概率。
def f(s_x):
loss = np.zeros(2)
y_probs = clf.predict_proba(X_test)[:,1]
thres = s_x # This can be set to whatever you'd like
y_pro = np.zeros(y_probs.shape)
y_pro[y_probs>thres]=1.
cm = confusion_matrix(y_test, y_pro)
counts = sum(cm)
count = sum(counts)
if counts[0]>0:
loss[0]=float(cm[0,1])/count
else:
loss[0]=0.01
if counts[1]>0:
loss[1]=float(cm[1,0])/count
else:
loss[1]=0.01
return loss
# 0.1 到 0.9 之前的 100个数值
x = np.linspace(0.1,0.9,100)
# x输入f(x)之后得到的结果
y = np.array([f(i) for i in x])
# 可视化
plt.plot(x,y)
plt.show()
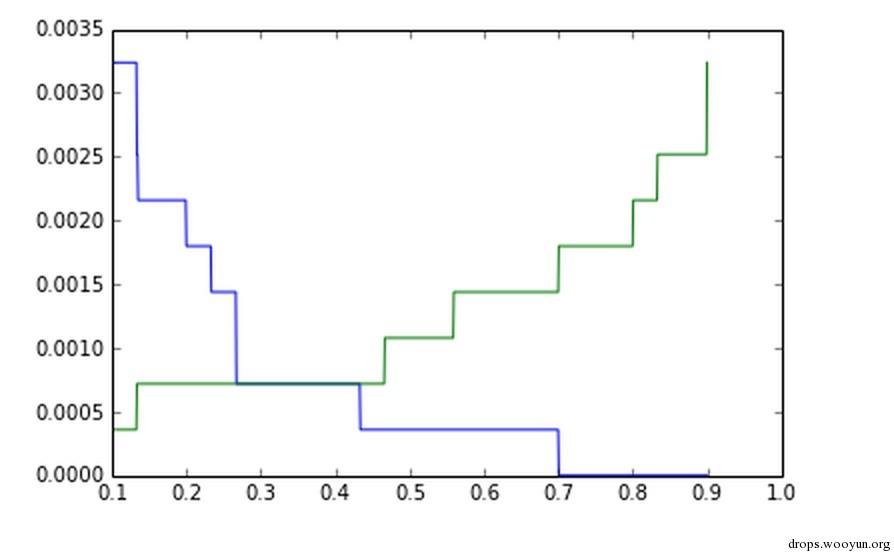
额,继续用0.7吧。
0x05 结语
这是个系列,可能我这么说也没人信吧,中途开始就有点乱了。
上一句老话吧,也不知道谁说的,反正大家天天挂嘴边。
数据挖掘项目的表现,80%取决于特征工程,剩下的20%才取决于模型等其他部分;又说数据挖掘项目表现的上限由特征工程决定,而其接近上限的程度,则由模型决定。